データマネジメントをスケールさせるには
最近、Data MeshやScaled Architectureと呼ばれる分散型のデータ(分析)基盤について勉強しているので
アウトプットも兼ねて、それがどういうもので、なぜ必要なのか説明していこうと思います。
僕の解釈も多く入っているので、間違っている点や気になる点等あれば、ぜひご意見お聞かせください。
主に以下の3つを参考にしています(Data Meshはearly release版の少ししか読めてないです、電子版が出たら読みます)
- Amazon.co.jp: Data Management at Scale: Best Practices for Enterprise Architecture (English Edition) 電子書籍: Strengholt, Piethein: 洋書
- Amazon | Data Mesh: Delivering Data-driven Value at Scale | Dehghani, Zhamak | Testing
- データマネジメント知識体系ガイド 第二版 | DAMA International, DAMA 日本支部, Metafind コンサルティング株式会社 |本 | 通販 | Amazon
データ基盤の変遷
まず、最初にデータ基盤がどういう変遷を辿ってきているのかについて説明します。
主に以下の三世代があったと言われています。
なんとなくイメージはつくと思うのですが、それぞれについて少し詳細に説明していきます。
第一世代:データウェアハウスアーキテクチャ
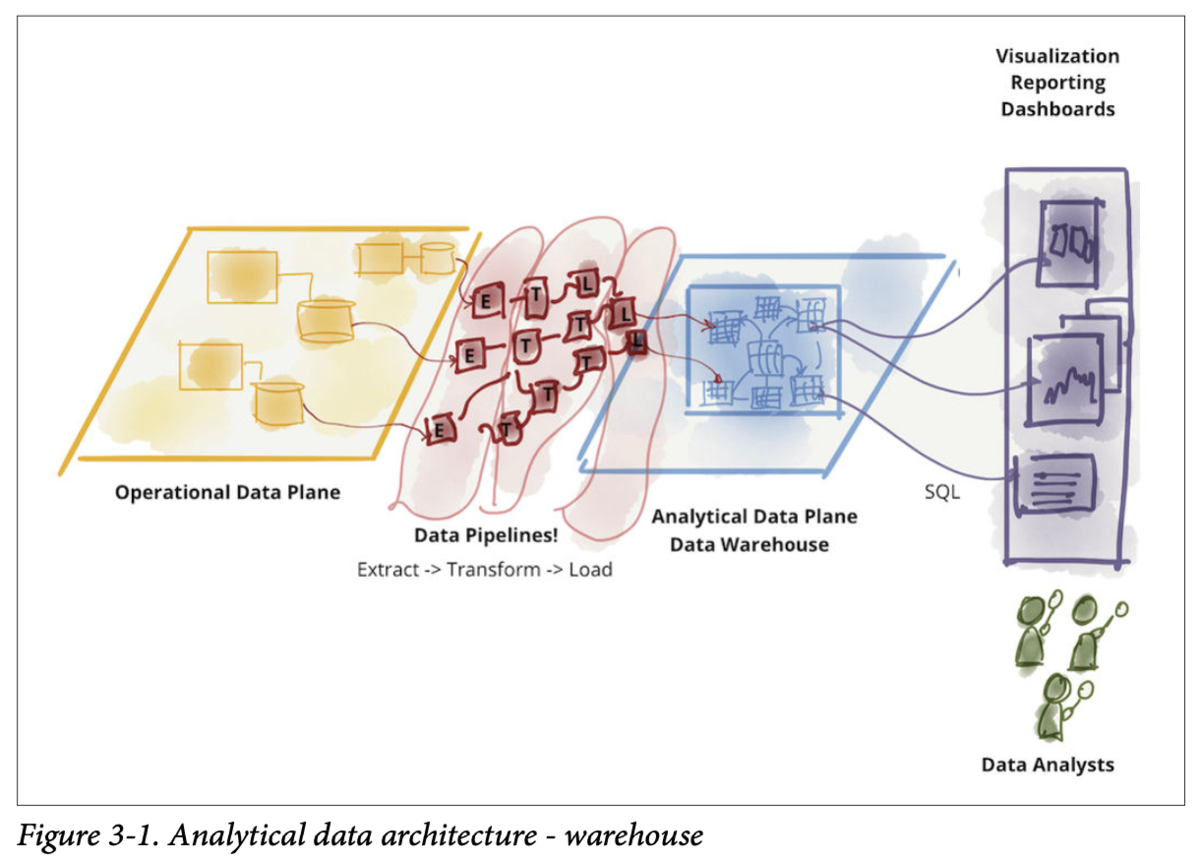
このアーキテクチャは、業務システムのデータを、ビジネス・インテリジェンス・アクティビティ(ダッシュボードやレポート、分析など)に使えるようにすることを目的としています。 大量のソーステーブルからデータを抽出・加工して作られており、履歴の分析もできるよう複数年分のデータが格納されているものもあります。
分析者はここだけ見ていれば売上の分析などができる状態になっているのが理想です。 ファクトテーブル、ディメンションテーブルで整理するスタースキーマ、スノーフレークスキーマでデータウェアハウスが構築されることが多いらしいです。(この辺り現在も使われることが多いのかはあんまりわからないです)
第二世代:データレイクアーキテクチャ
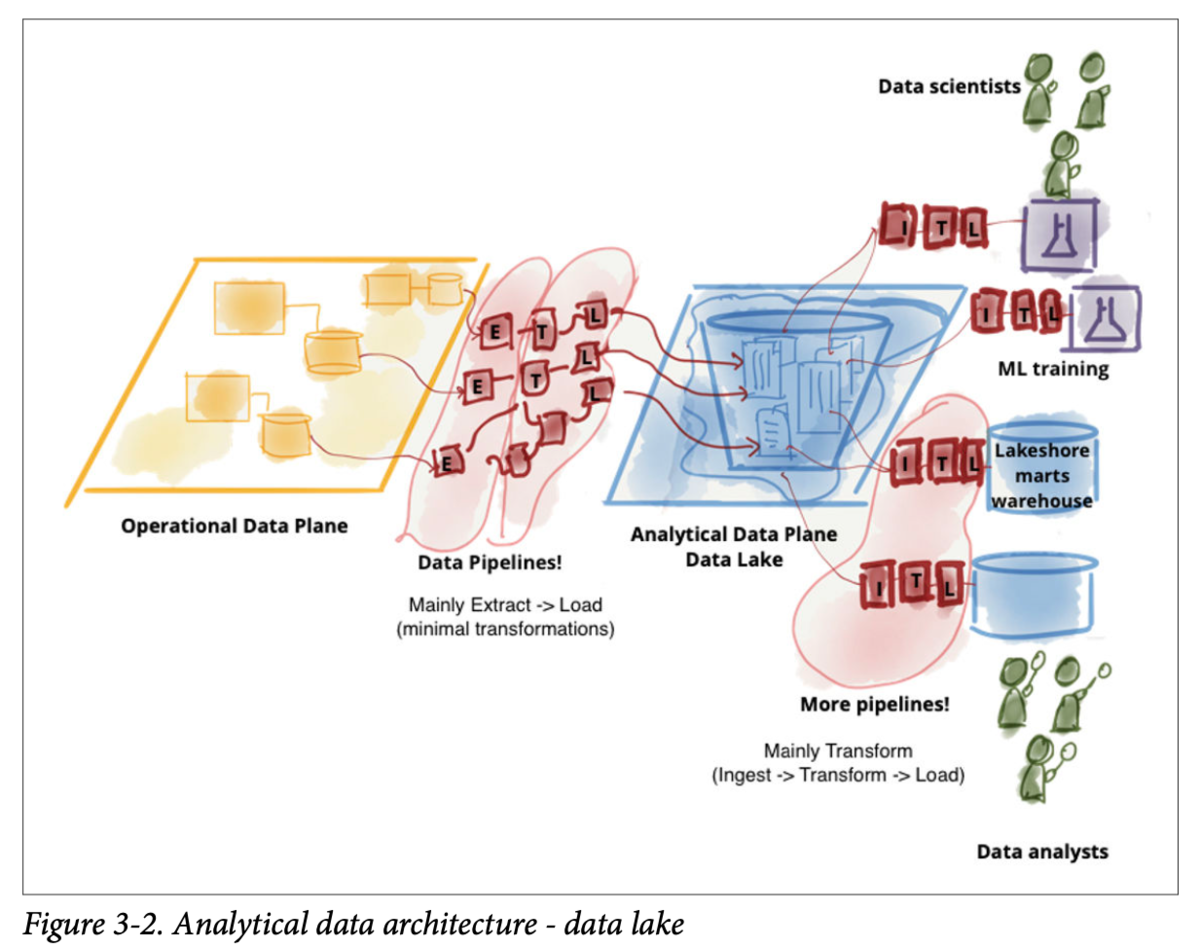
2010年ごろに登場したアーキテクチャで、データの新たな形式への対応、データサイエンスの学習のためのデータへのアクセス、データへの大規模な並列アクセスへ対応するために登場しました。
オブジェクトストレージなので、あらゆるタイプのデータを保存することが可能なことが大きな特徴です。 基本的には、ほとんど変換せずに保存され、使いたい人がそこから好きに加工して使うというスタイルです。 当然、データウェアハウスをここから作って整備することも可能です。(というか普通は作ります)
第三世代:マルチモーダルクラウドアーキテクチャ
正直、第二世代とあまり変わらないですが、リアルタイムにデータを利用できるようにしたり、データインフラの管理コスト削減などに取り組んでいるアーキテクチャです。 Kappaによるストリーミングデータの処理やApaceh Beamによるバッチとストリーミング処理の統一などもこれにあたるそうです。 また、クラウド化によって、ストレージとコンピュータの分離やデータレイクとウェアハウスの融合なども進んでいます(BigQueryやSnowflakeなど)。
このようにデータ基盤は色々と進化してきていますが、データを活用するために一元化すること(モノリシック)と、それを一部の専門チームが担っていること(中央主権)は変わっていません。
環境の変化とモノリシックなデータ基盤の限界
中央集権のモノリシックなデータ基盤では、データTが分析に使うデータを全て管理しています
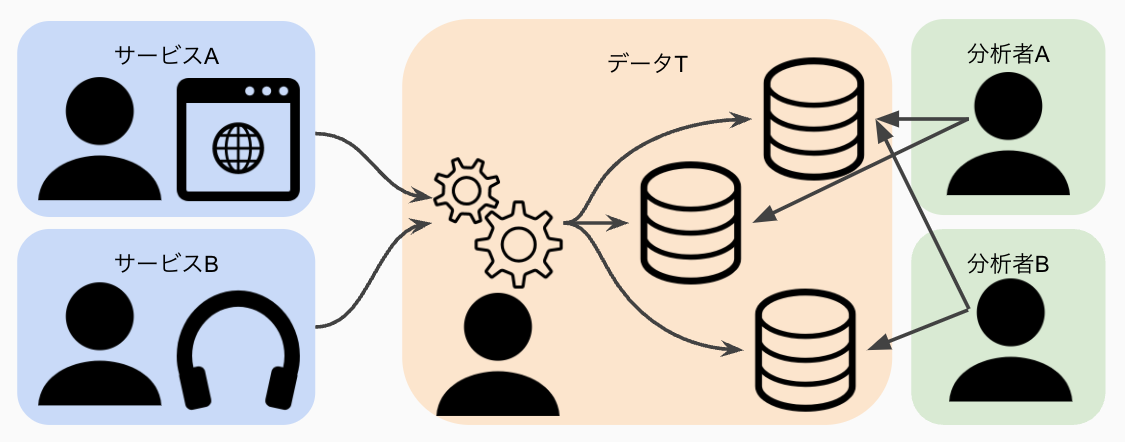
この方式は、サービスと分析者がPoint-to-Pointでやりとりするよりは効率的にデータを管理できます。
しかし、近年のサービス側の変化と分析者側の変化によって、この方式では適切にデータを管理できなくなってきました。
データマネジメントの目的
変化について詳しく見ていく前に、簡単にデータマネジメントの目的について整理したいと思います。
僕の考えるデータマネジメントの目的は
「信頼できるデータを使いたい人のところへ使いたいタイミングで提供すること」
です。
どういうデータが信頼できるのかなどの各論はまた別の機会に整理します。 ここで重要なのは、信頼できるかどうかと好きなタイミングで使えるかどうかのどちらも欠けてはいけないということです。
信頼できるデータのためには、事業側と協力してビジネスロジックをSQLなどに置き換える必要がありますし、 好きなタイミングで使うためには、データパイプラインで障害が起きないように常に監視しておく必要があります。 データチームはすでにやることでいっぱいです。 そんな中やることがどんどん増えていけば、当然データを適切に管理できなくなります。
サービス側での変化
サービス側の変化は、DevOpsによるリリース頻度の向上とそれに伴うマイクロサービス化です。

この変化によって、データTは大量のデータの頻繁な変更に対応しないといけなくなりました。 当然全てにすぐ対応することはできず、データが生成されてから活用されるまでのリードタイムが増えていってしまい、データをすぐ使える状態を保つのは難しくなります。
分析者側での変化
分析者側の変化は、分析ニーズの多様化に伴う独自のデータ加工や分析した結果である機械学習モデルのサービス側での使用などです。
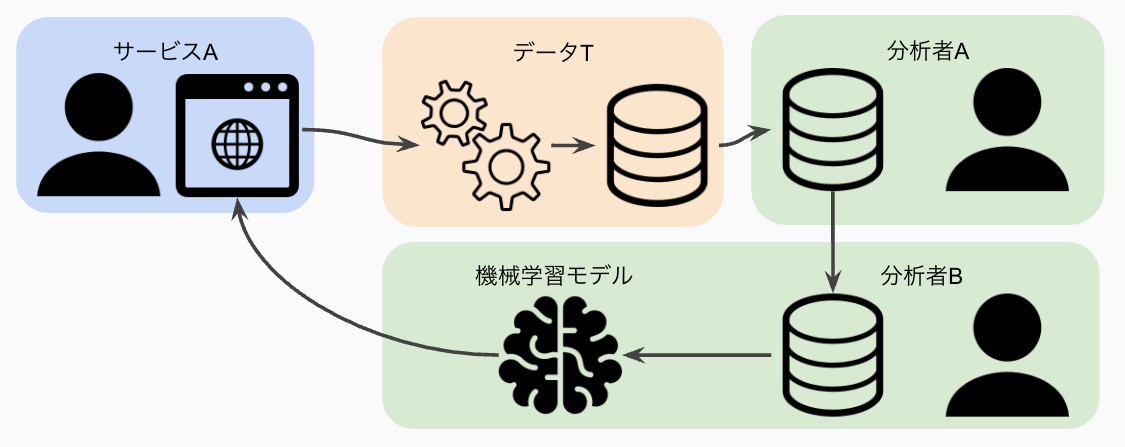
従来のデータチームで作っていたデータウェアハウスでは、BI用の集計されたデータで、売上の分析などには使えていましたが、顧客の購買行動について詳細に分析する際には、粒度が粗すぎて使えません。 そこで、分析者は集約されていない生のデータから好きなように加工して分析モデルなどを作るようになっていきました。 このような分析ニーズが高まっていくと当然一度加工したデータを再利用したいとなりますが、ここにはデータチームが関与できていないので、品質が担保されていないデータが蔓延していってしまいます。
データが少数のシステムから供給されているときや、データのユースケースが低頻度のレポートに限られていた時は、中央集権のモノリシックなデータ基盤で十分でした。 しかし、何百ものマイクロサービスからデータが供給、参照されるようになると、これまでの仕組みでは対応できません。 そこで提案されているのが、分散型のデータ基盤(Data MeshやScaled Architecture)です。(焦点は物理的な分散ではなくて、論理的な分散です)
分散型のデータ基盤の特徴
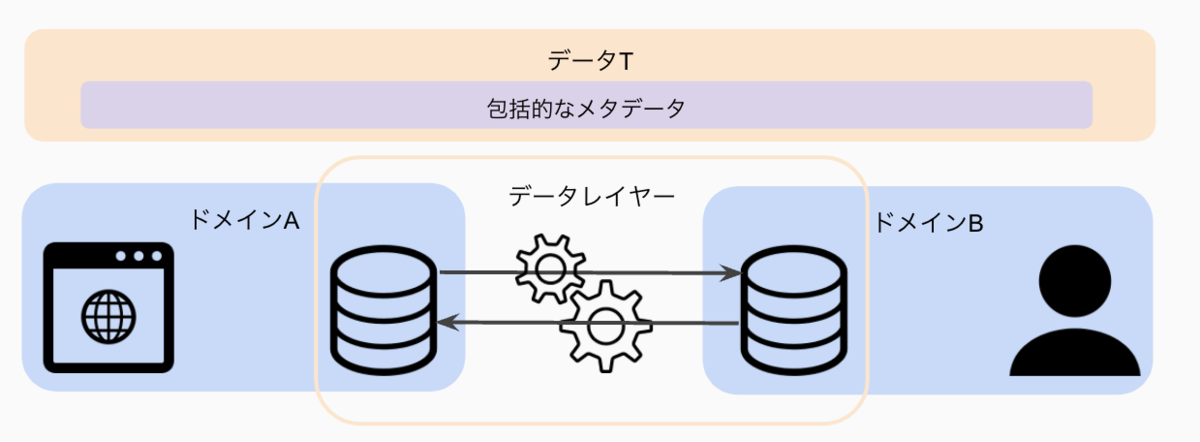
分散型のデータ基盤は、データ管理は責任に関する限り分散化されているが、メタデータは集中化されており、データ消費者がデータを見つけ、理解し、利用することができる状態を目指しています。 ここでは分散型のデータ基盤を考える際に重要な観点のみピックアップしようと思います。 Data MeshとScaled Architectureの詳細は、本で確認してもらえればと思います。 まだ考え方が固まっているわけではなく、これからも変わっていきそうなので、詳細はそこまで把握しなくても良い気がしています。
Domain-Driven Design
ドメイン単位でデータの管理も分割するという考え方です。 細かい違いを無視すると、各ドメインのデータウェアハウスやデータレイクはドメインが管理するとイメージするといいかと思います。 論理的な管理をするのがドメインなだけで、ジョブの実行などを自分たちで管理する必要はなく、横断チームが作っている基盤に乗っかるのでも良いと思っています。
ここでいうドメインは必ずしもサービスと同じではなくても良く、セールスやマーケティングなど機能組織のグループでも良いです。 重要なのは、そのグループの中で、共通の言語(ユビキタス言語)を使って意思疎通をしているかどうかになります。 僕自身DDDをあまりまだわかっていないので、詳しくはDDDの本を参考にしてください。
Data as a Product
データもプロダクトと考えて、プロダクトオーナーが、外部に公開するデータの品質や変更の管理などに責任を持つということです。 また外部に公開するときにプロダクトと同様の基準で品質等の担保をするべきだということでもあります。 これまでデータはプロダクトに付随するものと考えられることが多かったですが、今後はデータもプロダクトと同じ優先順位で考えて、責任を持って管理しましょう。
Data Layer
ドメイン間は直接やりとりするのですが、データTが標準化する手法を使ってコミュニケーションを取ります(これがデータレイヤーの役割)。 また、データ連携をする際は、その連携情報を中央管理のメタデータリポジトリに登録しなければいけません。 分散化するのは論理的なデータの管理責任で、メタデータ管理、データガバナンス、諸々の標準化はこれまで通り中央集権で主導していくべきだと僕は捉えています。
Automation
データマネジメントの目的は、「信頼できるデータを使いたい人のところへ使いたいタイミングで提供すること」 で、分散化することによって管理の手間が増えてしまっては元も子もありません。 分散化に伴い、可能なものはできる限り自動化していきましょう。 逆にここが自動化できないのであれば、分散化の恩恵はあまり得られないと思います。
まとめ&所感
これまでのデータ基盤は、中央集権的にデータを集めて管理していましたが、サービス側の変化とデータ活用の多様化に伴い限界が近づいています。 そこで、データの物理的な分散ではなくて、データ管理の論理的な分散に焦点を当てた、分散型のデータ基盤が提案されています。 分散型のデータ基盤では、データ管理は責任に関する限り分散化されているが、メタデータは集中化されており、データ消費者がデータを見つけ、理解し、利用することができる状態を目指しています。
まだ分散型のデータ基盤が本当に有効なのか、ジョブの実行順序はどう管理するのか、失敗した時のリカバリーは誰の責任なのかなど気になる点はあるのですが、実践していく価値があるなと思っています。 そして、今後データ組織は、ドメインに深く入り込んでデータを管理するチームとSelf-service型のデータプラットフォームを構築するチームへ分かれていかないといけないなと考えています。
公開しておいてアレなのですが、理解が深まれば随時更新していこうと思います。