データ品質の現在地を測る
この記事は、クリスマスに向けデータに関する想いや技術をぶっちゃける Advent Calendar 2022 22日目の記事です。
はじめに
朝出勤すると、昨日のデータが連携されていなかったり、ダッシュボードの形が極端に変わっていたりとデータ基盤の障害に悩まされたことはありませんか?
多くの人が頷いてくれるのではないでしょうか。
ただ、データの品質を高めたいと思っても、DMBOKなどに書かれているデータ品質の内容は、大事な事柄がリストアップしてあるだけで、具体的にどうしたら良いかのイメージが湧きにくいです。
そんな中、Monte Carlo社が書いた Data Quality Fundamentals (この記事で書籍といった場合はこの本を指します)という本がとても実践的で面白かったので、その内容を紹介したいと思います。
この記事がデータ品質について考えるきっかけになり、データ基盤の障害に悩まされる人を少しでも減らせれば幸いです。
データ品質の重要性
そもそもデータ品質とは何でしょうか。
DMBOKには「データ品質の度合いはデータ利用者の期待と要求を満たす度合である」とあり、絶対的な基準のようなものはなく、目的に合っているかどうかが重要になります。 すなわち、月次で経営に報告する指標であれば、リアルタイムでデータが必要なわけではないが、数値に少しでもズレがあれば低品質なデータになります。
では、なぜデータ品質は重要なのでしょうか。
これはWebサービスの発展を考えるとわかりやすいです。 1990年代には、Webサービスはあったらいいな程度の存在で、一時的にダウンしても大した問題ではありませんでした。現在、Webサービスはほとんどの企業にとってミッションクリティカルなものとなっています。その結果、企業はダウンタイムを綿密に測定し、サービスの中断を回避するために多くのリソースを投入しています。
同様に、企業は日々業務を遂行し、ミッションクリティカルな意思決定を行うために、ますますデータへの依存を高めているため、データ品質が重要になってきているのです。
実際、Monte Carlo社が、Wakefield Research社と提携し、300人以上のデータプロフェッショナルを対象にした調査によると 、データ担当者がデータ品質の評価やチェックに費やす時間は実に40%にのぼり、データ品質の低下は企業の収益の26%に影響するというデータ品質の重要性を示す調査結果が得られています。
データ品質を計測する指標
「測定できないものは管理できない」「推測するな、計測しろ」と言われるように、データ品質に関する指標なしに、データ品質を管理することはできません。 では、どのような指標を使えば良いのでしょうか。
書籍では、以下の「データダウンタイムコスト(Cost of data downtime)」という指標が提案されています。 (この辺は変に日本語訳しない方が良いかもですが、日本語でいきます)
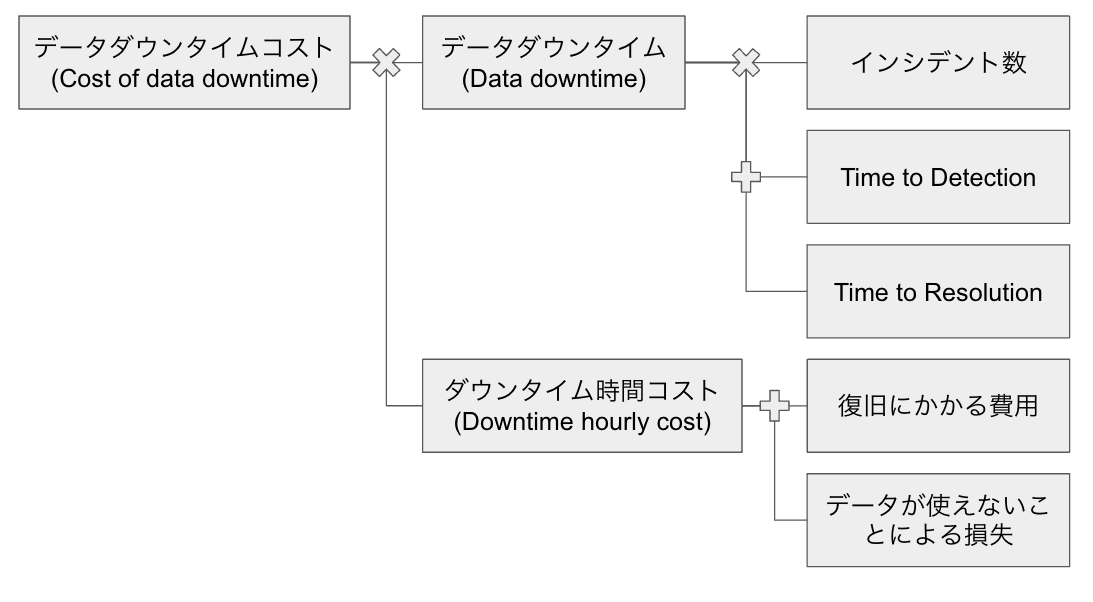
データダウンタイムコスト = データダウンタイム×ダウンタイム時間コスト
データダウンタイム: データが正常でない時間
ダウンタイム時間コスト: データの復旧に費やした労働のコスト+ユーザーがデータを使えないことによる単位時間あたりの損失
自分はこの指標を最初見たとき、衝撃を受けました。データ品質は利用者によって決まるということと、ビジネスへの影響を上手く表現している指標だったからです。 以下でもう少し詳細に説明していこうと思います。
データダウンタイム
データダウンタイムはより詳細には下記で表されます。
データダウンタイム=N×(TTD+TTR)
N: データインシデント数
TTD(Time to Detection): データ品質の問題の発生からデータチームが発見するまでにかかる時間
TTR(Time to Resolution): 問題の発見後、データチームが解決するまでにかかる時間
インシデントの定義は、およそ2通りの方法があり、それらの合計をインシデント数とすることができます。
1つ目の定義は事前に定義したテストに失敗した場合です。これはPKやNullなどをテーブルに対してチェックするクエリを投げてその結果を見ることで検知することができます。
2つ目の定義は、利用者が異変に気づいてデータチームにアラートをあげた場合です。テスト項目を事前に網羅的に定義することは基本的に不可能です。異変を感じたらすぐにアラートを上げてもらうようにしましょう。
TTDやTTRは、アラートが上がった時間や修正後にデータが連携された時間などをシステムから取得して算出できるかと思います。 データダウンタイムとしてはTTDやTTRは平均値がわかれば良いのですが、最小値や最大値なども重要なデータになります。
ダウンタイム時間コスト
ダウンタイム時間コストは以下で表されます。
ダウンタイム時間コスト = 復旧にかかる費用 + データが使えないことによる損失
データダウンタイムとは違って、システムから取得することは難しいですが、ある程度仮定をおくことで計算できます。
復旧にかかる費用は、エンジニアの労働時間で計算します。
例えば、1人のデータエンジニアがダウンタイム時間の1/4を監視や調査に費やしており、給与が時給4000円とすると、ダウンタイム時間あたり1000円のコストがかかっていると推定できます。
データが使えないことによる損失は、業務によって大きく異なります。
例えば、投資会社に報告するためにデータを利用している場合、データのダウンタイムは致命的で、10万円/時間が損失として加算されます。
また、分析チームのコストを追加することもできます。例えば、アナリストが10人いて、ダウンタイムが発生したときに彼らが休んでいるとすると、かなりの損失になります(平均時給5000円×10=5万円/時間)。
この辺りは勝手に決めてもあまり意味がないので、上層部や周辺の組織と相談しながら詳細を詰めていきましょう。
ちょっとした計算
データダウンタイムコストの計算を仮の数値で、実際にしてみようかと思います。
モンテカルロ社の調査の結果、年間15テーブルに1テーブルがデータインシデントの影響を受けていること、インシデントの発生から発見までに4時間以上、発見後の解決までに平均9時間かかっていることが判明しました。
例えば、1000テーブルあるとすると
データダウンタイム = 1000×1/15 × (4+9) ≒ 867 時間/年
になります。
時給4000円のエンジニアが2人、ダウンタイムの1/4を監視や調査に費やしており、時給5000円のデータアナリストが10人、ダウンタイムの1/5の時間稼働できていないとすると
ダウンタイム時間コスト = 4000×2×1/4 + 5000×10×1/5 = 12000 円/時間
ダウンタイムコストは少なく見積もっても約1040万円/年になります。
データダウンタイムを20%改善できたとすると、少なくとも年間208万円のコスト削減になるだけでなく、今後扱うデータが増えることによるダウンタイムの増加を軽減することができます。
そして、これらの指標は、改善ポイントの見極めに使うこともできます。
TTDが大きければ、アラートの仕組みなど異常を検知できる仕組みが不十分な可能性があり、TTRが大きければ、データパイプラインが複雑化しており、技術的負債が溜まっている可能性があります。
また、データが使えないことによる損失が大きいテーブルは重要なテーブルで、そこに紐づくパイプラインは厳重にするなどの対策が可能です。
まとめ
本記事では、データの不備が与える金銭的影響を測定する指標の計算方法を紹介しました。ぜひ皆さんも自分たちのデータ基盤の品質を測定してみてください。 ただ、指標を定義するだけはもちろんダメで、それを改善するために効果的なプラットフォームの構築や文化・組織づくりといった取り組みが必要です。(こちらの記事もまた書くかもしれません)
本記事では紹介しきれませんでしたが、インシデント管理のベストプラクティスやデータ品質を大規模に普及させる際の文化・組織の障壁、Toast社のデータ基盤の変遷に関するケーススタディなど、書籍には興味深いトピックスが盛りだくさんなので、データ品質に興味を持たれた方はぜひ書籍の方も読んでみてください。
今後、データ品質は必ず重要になると思っているので、自分でも実践していければと思います。 最後まで読んでくださり、ありがとうございました。
データマネジメントをスケールさせるには
最近、Data MeshやScaled Architectureと呼ばれる分散型のデータ(分析)基盤について勉強しているので
アウトプットも兼ねて、それがどういうもので、なぜ必要なのか説明していこうと思います。
僕の解釈も多く入っているので、間違っている点や気になる点等あれば、ぜひご意見お聞かせください。
主に以下の3つを参考にしています(Data Meshはearly release版の少ししか読めてないです、電子版が出たら読みます)
- Amazon.co.jp: Data Management at Scale: Best Practices for Enterprise Architecture (English Edition) 電子書籍: Strengholt, Piethein: 洋書
- Amazon | Data Mesh: Delivering Data-driven Value at Scale | Dehghani, Zhamak | Testing
- データマネジメント知識体系ガイド 第二版 | DAMA International, DAMA 日本支部, Metafind コンサルティング株式会社 |本 | 通販 | Amazon
データ基盤の変遷
まず、最初にデータ基盤がどういう変遷を辿ってきているのかについて説明します。
主に以下の三世代があったと言われています。
なんとなくイメージはつくと思うのですが、それぞれについて少し詳細に説明していきます。
第一世代:データウェアハウスアーキテクチャ
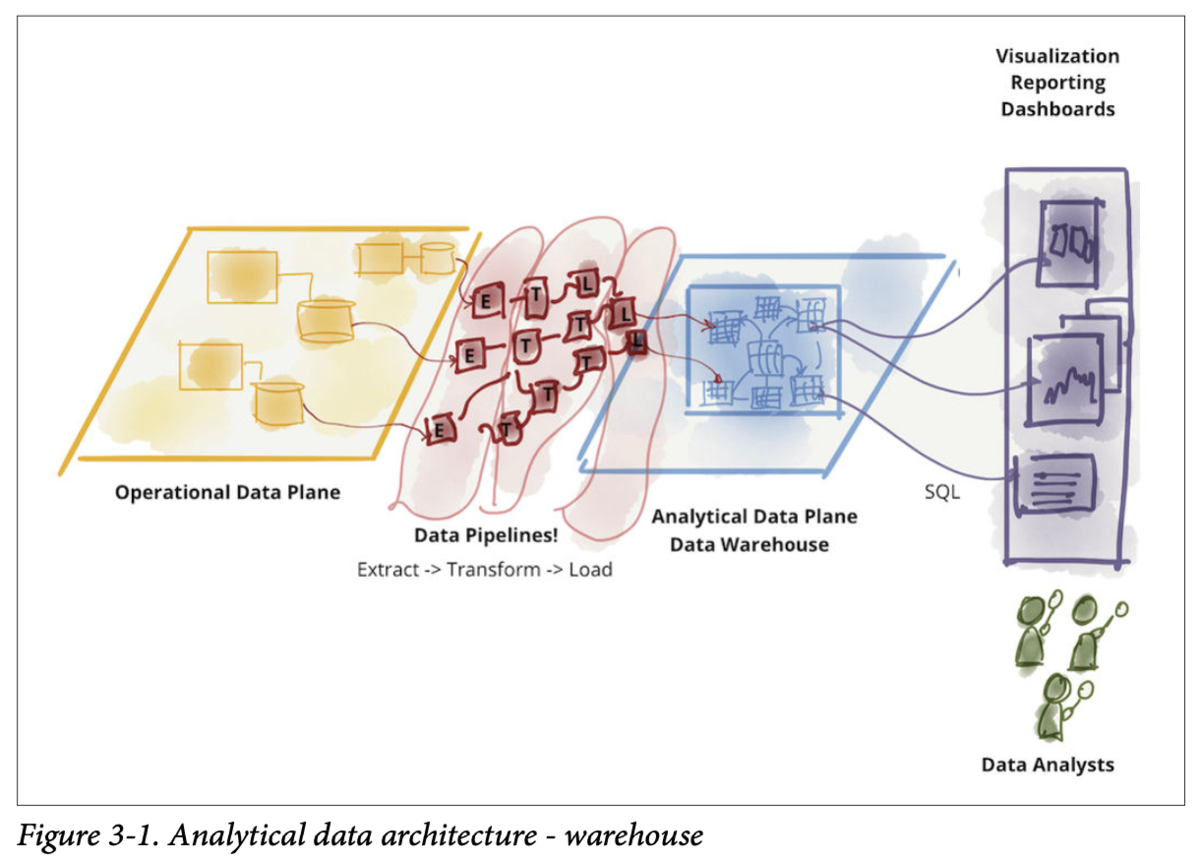
このアーキテクチャは、業務システムのデータを、ビジネス・インテリジェンス・アクティビティ(ダッシュボードやレポート、分析など)に使えるようにすることを目的としています。 大量のソーステーブルからデータを抽出・加工して作られており、履歴の分析もできるよう複数年分のデータが格納されているものもあります。
分析者はここだけ見ていれば売上の分析などができる状態になっているのが理想です。 ファクトテーブル、ディメンションテーブルで整理するスタースキーマ、スノーフレークスキーマでデータウェアハウスが構築されることが多いらしいです。(この辺り現在も使われることが多いのかはあんまりわからないです)
第二世代:データレイクアーキテクチャ
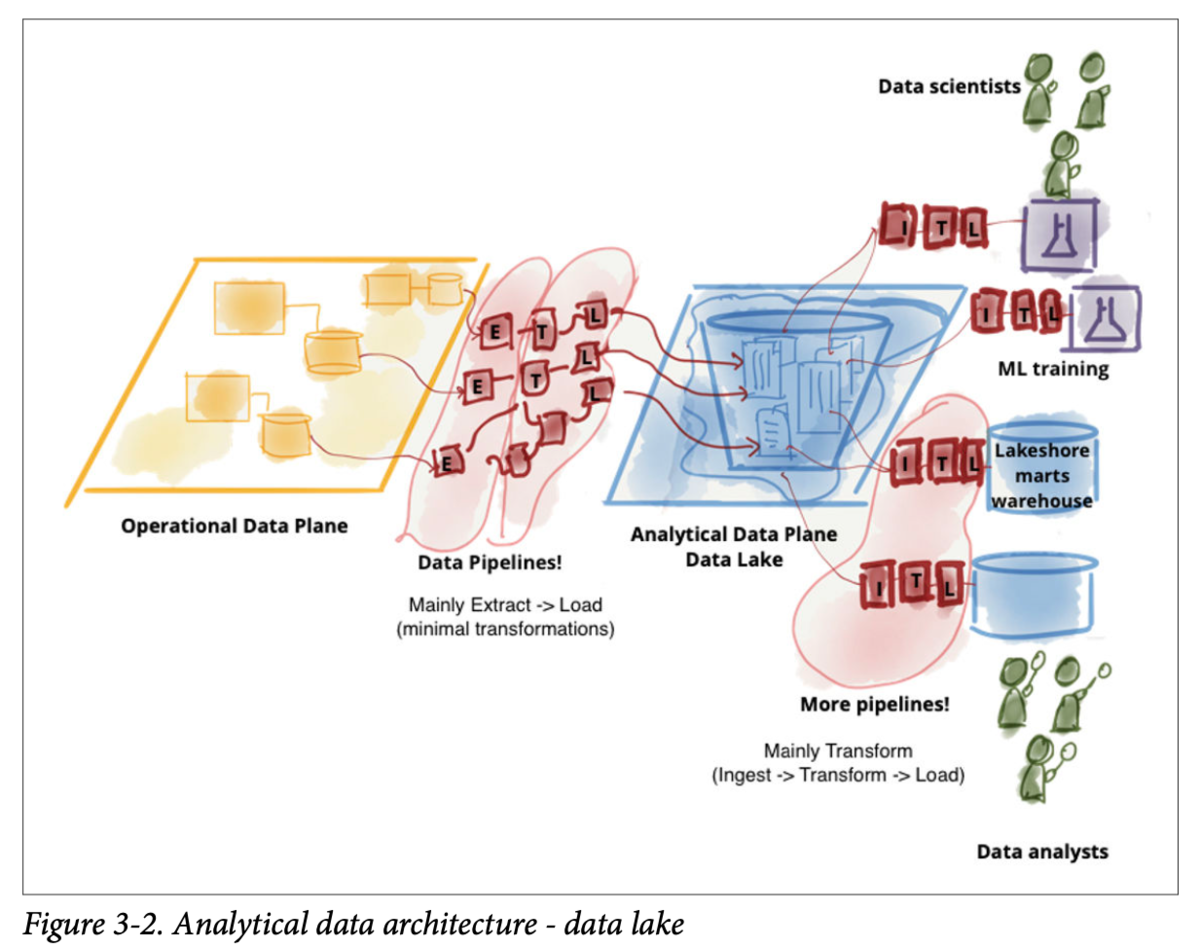
2010年ごろに登場したアーキテクチャで、データの新たな形式への対応、データサイエンスの学習のためのデータへのアクセス、データへの大規模な並列アクセスへ対応するために登場しました。
オブジェクトストレージなので、あらゆるタイプのデータを保存することが可能なことが大きな特徴です。 基本的には、ほとんど変換せずに保存され、使いたい人がそこから好きに加工して使うというスタイルです。 当然、データウェアハウスをここから作って整備することも可能です。(というか普通は作ります)
第三世代:マルチモーダルクラウドアーキテクチャ
正直、第二世代とあまり変わらないですが、リアルタイムにデータを利用できるようにしたり、データインフラの管理コスト削減などに取り組んでいるアーキテクチャです。 Kappaによるストリーミングデータの処理やApaceh Beamによるバッチとストリーミング処理の統一などもこれにあたるそうです。 また、クラウド化によって、ストレージとコンピュータの分離やデータレイクとウェアハウスの融合なども進んでいます(BigQueryやSnowflakeなど)。
このようにデータ基盤は色々と進化してきていますが、データを活用するために一元化すること(モノリシック)と、それを一部の専門チームが担っていること(中央主権)は変わっていません。
環境の変化とモノリシックなデータ基盤の限界
中央集権のモノリシックなデータ基盤では、データTが分析に使うデータを全て管理しています
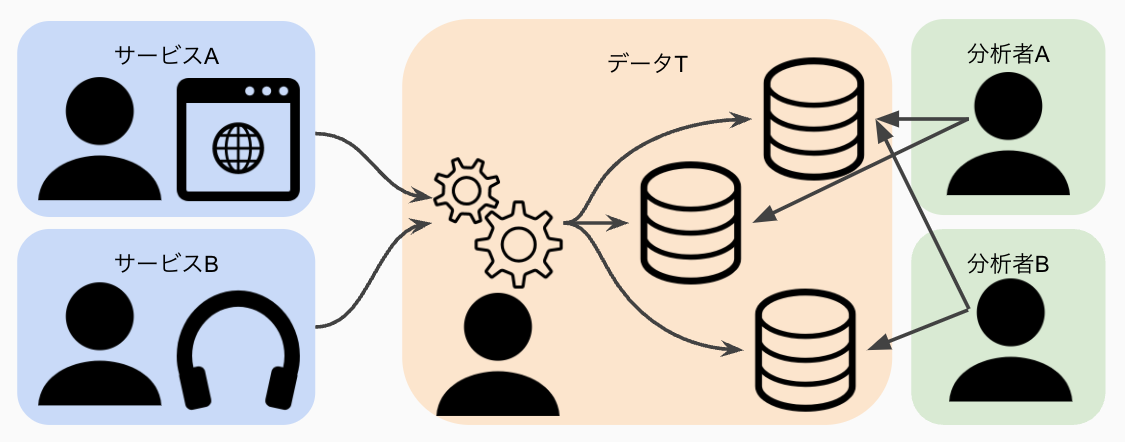
この方式は、サービスと分析者がPoint-to-Pointでやりとりするよりは効率的にデータを管理できます。
しかし、近年のサービス側の変化と分析者側の変化によって、この方式では適切にデータを管理できなくなってきました。
データマネジメントの目的
変化について詳しく見ていく前に、簡単にデータマネジメントの目的について整理したいと思います。
僕の考えるデータマネジメントの目的は
「信頼できるデータを使いたい人のところへ使いたいタイミングで提供すること」
です。
どういうデータが信頼できるのかなどの各論はまた別の機会に整理します。 ここで重要なのは、信頼できるかどうかと好きなタイミングで使えるかどうかのどちらも欠けてはいけないということです。
信頼できるデータのためには、事業側と協力してビジネスロジックをSQLなどに置き換える必要がありますし、 好きなタイミングで使うためには、データパイプラインで障害が起きないように常に監視しておく必要があります。 データチームはすでにやることでいっぱいです。 そんな中やることがどんどん増えていけば、当然データを適切に管理できなくなります。
サービス側での変化
サービス側の変化は、DevOpsによるリリース頻度の向上とそれに伴うマイクロサービス化です。

この変化によって、データTは大量のデータの頻繁な変更に対応しないといけなくなりました。 当然全てにすぐ対応することはできず、データが生成されてから活用されるまでのリードタイムが増えていってしまい、データをすぐ使える状態を保つのは難しくなります。
分析者側での変化
分析者側の変化は、分析ニーズの多様化に伴う独自のデータ加工や分析した結果である機械学習モデルのサービス側での使用などです。
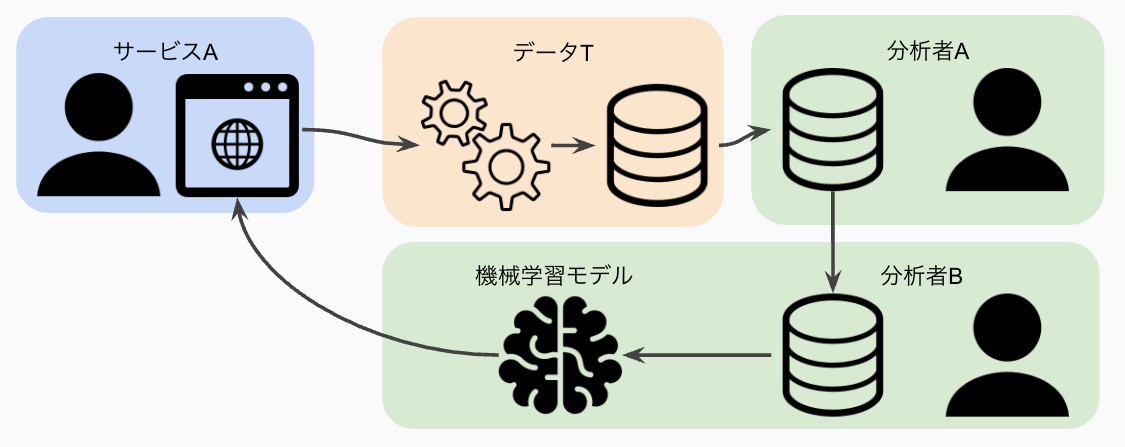
従来のデータチームで作っていたデータウェアハウスでは、BI用の集計されたデータで、売上の分析などには使えていましたが、顧客の購買行動について詳細に分析する際には、粒度が粗すぎて使えません。 そこで、分析者は集約されていない生のデータから好きなように加工して分析モデルなどを作るようになっていきました。 このような分析ニーズが高まっていくと当然一度加工したデータを再利用したいとなりますが、ここにはデータチームが関与できていないので、品質が担保されていないデータが蔓延していってしまいます。
データが少数のシステムから供給されているときや、データのユースケースが低頻度のレポートに限られていた時は、中央集権のモノリシックなデータ基盤で十分でした。 しかし、何百ものマイクロサービスからデータが供給、参照されるようになると、これまでの仕組みでは対応できません。 そこで提案されているのが、分散型のデータ基盤(Data MeshやScaled Architecture)です。(焦点は物理的な分散ではなくて、論理的な分散です)
分散型のデータ基盤の特徴
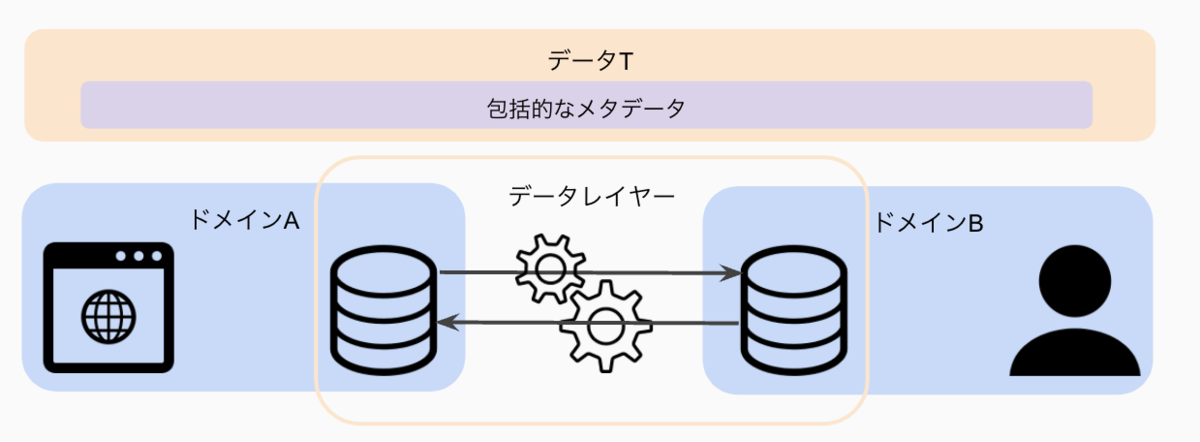
分散型のデータ基盤は、データ管理は責任に関する限り分散化されているが、メタデータは集中化されており、データ消費者がデータを見つけ、理解し、利用することができる状態を目指しています。 ここでは分散型のデータ基盤を考える際に重要な観点のみピックアップしようと思います。 Data MeshとScaled Architectureの詳細は、本で確認してもらえればと思います。 まだ考え方が固まっているわけではなく、これからも変わっていきそうなので、詳細はそこまで把握しなくても良い気がしています。
Domain-Driven Design
ドメイン単位でデータの管理も分割するという考え方です。 細かい違いを無視すると、各ドメインのデータウェアハウスやデータレイクはドメインが管理するとイメージするといいかと思います。 論理的な管理をするのがドメインなだけで、ジョブの実行などを自分たちで管理する必要はなく、横断チームが作っている基盤に乗っかるのでも良いと思っています。
ここでいうドメインは必ずしもサービスと同じではなくても良く、セールスやマーケティングなど機能組織のグループでも良いです。 重要なのは、そのグループの中で、共通の言語(ユビキタス言語)を使って意思疎通をしているかどうかになります。 僕自身DDDをあまりまだわかっていないので、詳しくはDDDの本を参考にしてください。
Data as a Product
データもプロダクトと考えて、プロダクトオーナーが、外部に公開するデータの品質や変更の管理などに責任を持つということです。 また外部に公開するときにプロダクトと同様の基準で品質等の担保をするべきだということでもあります。 これまでデータはプロダクトに付随するものと考えられることが多かったですが、今後はデータもプロダクトと同じ優先順位で考えて、責任を持って管理しましょう。
Data Layer
ドメイン間は直接やりとりするのですが、データTが標準化する手法を使ってコミュニケーションを取ります(これがデータレイヤーの役割)。 また、データ連携をする際は、その連携情報を中央管理のメタデータリポジトリに登録しなければいけません。 分散化するのは論理的なデータの管理責任で、メタデータ管理、データガバナンス、諸々の標準化はこれまで通り中央集権で主導していくべきだと僕は捉えています。
Automation
データマネジメントの目的は、「信頼できるデータを使いたい人のところへ使いたいタイミングで提供すること」 で、分散化することによって管理の手間が増えてしまっては元も子もありません。 分散化に伴い、可能なものはできる限り自動化していきましょう。 逆にここが自動化できないのであれば、分散化の恩恵はあまり得られないと思います。
まとめ&所感
これまでのデータ基盤は、中央集権的にデータを集めて管理していましたが、サービス側の変化とデータ活用の多様化に伴い限界が近づいています。 そこで、データの物理的な分散ではなくて、データ管理の論理的な分散に焦点を当てた、分散型のデータ基盤が提案されています。 分散型のデータ基盤では、データ管理は責任に関する限り分散化されているが、メタデータは集中化されており、データ消費者がデータを見つけ、理解し、利用することができる状態を目指しています。
まだ分散型のデータ基盤が本当に有効なのか、ジョブの実行順序はどう管理するのか、失敗した時のリカバリーは誰の責任なのかなど気になる点はあるのですが、実践していく価値があるなと思っています。 そして、今後データ組織は、ドメインに深く入り込んでデータを管理するチームとSelf-service型のデータプラットフォームを構築するチームへ分かれていかないといけないなと考えています。
公開しておいてアレなのですが、理解が深まれば随時更新していこうと思います。
Differential Privacy
前回の記事でk-匿名性などを満たすように加工しようみたいな話をしましたが, 現在はDifferential Privacy(DP)という考えが主流なのでそれについて説明していこうと思います. 今回も『データ解析におけるプライバシー保護』[1]を参考にしています. www.kspub.co.jp
目次
- 簡単な背景
- Differential Privacy
- Local Differential Privacy
- まとめ
簡単な背景
そもそもどういう状況が想定されているのかが少し実感しづらいので そのあたりをまず説明していきたいと思います.
ビッグデータと言われるように色々なデータが収集されるようになってきています. ただ,集めるだけじゃなくて,その分析結果なども公開されるようになっています. 例えば,Amazonでは人気商品などが推薦されたり,Google Mapでは店の混雑状況などが可視化されたりしています. データの公開だけではなく,このような分析結果の公開もプライバシーに関するリスクを抱えています.
極端な例ですが,山田さんが毎週水曜日にあるラーメン屋に通っていることは知っているとします. そのラーメン屋は人気がなく,通っている人は山田さんだけだとします. この状況を知った上で,Google Mapの混雑状況を見るとある1時点だけ人が来ていることがわかり, 山田さんが何時にラーメン屋に通っているかという情報がバレてしまいます. また,統計量などはその情報を分析したいサードパーティなどに提供されることもあります.
従って,このような統計量の公開でもプライバシーを保護する必要があり,それを考えているのがDifferential Privacy(DP)です.
このDPは統計量にノイズを加えて本当の統計量ではないものを公開することでプライバシーを保護します.
イメージとしては以下のような感じで,サービスの提供者はリアルなデータを集めることができ,その公開時にノイズをかけます.

Differential Privacy
ここでは,数学的なDifferential Privacyの定義を書いたのちに,どういうことを意味しているのかを書いていこうと思います. 上で述べたように,あくまでデータの統計量(カウント,合計,平均など)を公開する時に個人のデータがばれないようにするためのものだという認識は忘れないでください. プライバシーを完全に守るとデータの有用性が無になるので,プライバシーをある程度守って有用性を高めることを目指しています.
Differential Privacyの定義[2]
要素が一つだけ異なる(隣接する)データベースDとD'に対して
あるメカニズムAが以下の不等式を満たせば,そのメカニズムAはε-Differntial Privacyを満たすという
この時,tはメカニズムの出力を全て考えているので,データベースの内容がどうなっていようとプライバシーは守られることになります.
そのまま解釈するとAにDを入力した時にtを出力する確率とAにD'を入力した時にtを出力する確率が倍違うとなるが,
どちらかというと出力がtだった時に入力がDだったかD'だったかの確率の違いが
でこの
が小さいと見分けがつかないということになります.
この辺りの解釈については次でまとめて説明しようと思います.とりあえずは,DPはデータベースを入力としたメカニズムの出力に満たすべき制約を定義していると考えてください.
隣接性やεの解釈
まず入力のDとD',εとはなんぞやとなると思うので,それについて説明します.
DPはDとD'という隣接したデータベースに対する定義なので,どのような要素の隣接を考えるかによって守られるプライバシーが異なってきます. FacebookのようなSNSの運営会社が参加しているユーザー間のグラフの統計量を公開する場面を考えます. データベースとしては(user_id, other_id, friend_or_not)のようなものを考える.friend_or_notは1なら友達,0なら友達ではない.
1つ目の考え方は「ある枝がグラフに存在するか否か」によって隣接性を定義することです.
この場合,あるuser_idとother_idに対して,Dはfriend_or_notが1でD'はfriend_or_notが0になる.
このようなDとD'に対してDPを満たすメカニズムを用いると,あるユーザが1人の別のユーザと友達であろうがなかろうが,
クエリの結果がtという情報を受け取る確率は倍程度しか変わらない.
従って,個々の交友関係を公にしたくない場合に有効な定義だと言えます.
2つ目の考え方は「ある頂点がグラフに存在するか否か」によって隣接性を定義することです.
この場合,Dに含まれているユーザーのうち,ある1人のデータのみがD'には含まれておらず,それ以外は全て同じデータだということを意味します.
このようなDとD'に対してDPを満たすメカニズムを用いると,あるユーザがSNSに参加していようがいまいが,
クエリの結果がtという情報を受け取る確率は倍程度しか変わらない.
従って,ユーザがそのSNSに参加しているかどうかを公にしたくない場合に有効な定義だと言えます.
隣接性は公にしたくないと考えている情報の粒度を定義していると言えます. 一般的には1つ目のような考え方で,データベースのうちのある値が異なる場合を考えることが多いと思います.
εは隣接性で定義された粒度の情報に対してプライバシーをどの程度保護するかを定義しています. εを小さくすると,DとD'に対してtと出力する確率がほぼ同じになり,出力結果がtだった時に入力がDだったかD'だったか見分けがつかなくなるので,プライバシー保護の度合いが高いと言えます. 一方,εを大きくすると,同じような値を出力する確率が低いので,出力から入力の見分けがつきやすくなり,プライバシー保護の度合いが低いと言えます. このイプシロンはよくプライバシーバジェットと呼ばれますが,なぜそう呼ばれるかは次の記事で紹介しようと思います.
εを事前に決定しておき,ε-DPを守るメカニズムに基づいて統計量の公開をすると,事前に設定した厳しさでプライバシーを保護できます. DPではどんな背景知識を持っている相手に対してでも同等のプライバシーを保護できることから,プライバシー保護の一般的な概念になってきています. ただ,εの実際の値(0.1や1, 2など)と実際に守られているプライバシーの関係がわかりづらいという批判もあります.
Laplace Mechanism
今まではDPの定義のような話でしたが,ε-DPを実際に達成する方法であるLaplace machanismについて説明していこうと思います. Laplace Mechanismでは,イメージ図で書いたようにノイズを加えることでDPを達成します.
敏感度
では,ノイズをどれくらい加えたら良いのでしょうか.それを考えるのにクエリの敏感度というものを用います. これは隣接したデータベースDとD'に対してクエリを実行した結果がどれくらい変わるかを表したものです.
l1-敏感度の定義[1]
例えば,合計や平均の敏感度は以下のようになります.
の敏感度
- あるユーザーiの値が0か1かなので,敏感度は1
の敏感度
- sumをnで割るので,敏感度は
- sumをnで割るので,敏感度は
この敏感度に応じた大きさのノイズをかけることでDPを満たすことが出来ます. また,合計を出力する時にDPを満たす方がよりノイズを大きくかけないといけないことがわかります.
ラプラス分布
実際にかけるノイズでよく使われるのがラプラス分布です.
期待値は,分散は
です.
ノイズとして加えるときは期待値を0にして,偏りがないようにします.
として,
を色々と変えた時の分布は以下のようになります.

クエリqのl1-敏感度を,プライバシーバジェットをεとした時,
Laplace(0, /ε)からサンプリングしたrを用いて
q(D)というクエリの結果の代わりにt=q(D) + rを結果として出力することでε-DPを満たすことができます.
この流れ全体をラプラスメカニズムといいます.
次に,このラプラスメカニズムが本当にε-DPを満たしているかを確かめていきます. ラプラス分布の確率密度関数の定義からxに関わるのは指数関数の部分だけなので,そこだけに着目し 対数をとった比を考えると以下になります.
上記では敏感度の定義として,maxを取っていることを使っています.
従って,ラプラスメカニズムはε-DPを満たします.
平均値などを求めた後に,ラプラスメカニズムを使ってノイズをかけた出力を公開するとプライバシーを保護することが出来ます.
Local Differential Privacy(LDP)
DPでは統計量を公開するときにノイズをかけていましたが,実際のサービスなどでは,データを集めている人を信頼出来ない時が多々あると思います.
スマホのアプリとかでは開発者がよくわからないというのはよくあるシチュエーションで,こういう時には個人的な情報をできれば渡したくないですが,渡すことでサービスがよくなるのであれば渡してあげたいはずです.
そこで,考えられたのがLocal Differential Privacyという概念で,これはユーザーがデータ収集者にデータを渡す時にすでにノイズを加えて個々の値をわからなくしてから渡すというものです.従って,各ユーザーは安心してデータを渡せ,収集者は個々のデータはわからないが,統計的な性質は分析することが出来,サービスの向上に活かすことが出来ます.
イメージとしては以下のようになります.

こうすることで個人の情報は渡さずに,全体の傾向を分析することができます. さらに,LDPを守って集められたデータはそこからどんな使い方をしようとこれ以上プライバシーを侵害するリスクがないという利点もあります.
Local Differential Privacyの定義[3]
任意の異なる入力v1,v2に対してメカニズムAが以下の不等式を満たす時,Aはε-LDPを満たすという
考え方はDPと共通で,出力がyだった時に,ユーザーの入力がどの値だったか見分けがつきにくいということを意味しています.
しかし,DPでは隣接したDとD'に対してそれが成り立っていたのに対して,LDPでは,入力のどんな2つの値の組に対しても上記の不等式が成り立っていないといけないので,
LDPはDPよりも厳しくプライバシーを保護していると言えます.
Random Response
LDPを達成するメカニズムの説明としてよく使われるのがRandom Responseと呼ばれるものです. 例えば,100人の学生に対して,理系の人数を調べたいとします. 各学生は自分の分野を知られたくないので,コインを投げて表が出れば正直に答え,裏が出ればさらにコインを投げ,表が出たら理系,裏が出たら文系と回答します. こうすると,各個人の回答が本当かどうかわからないので,個人の分野は分かりませんが,人数はなんとなく分かります. これを一般的にして,0,1で返す質問に対し,ある一定の確率pで本当の回答をし,残りの確率1-pで適当に回答するとします. 数式的に表すと以下になります.
これがε-LDPを満たすことは簡単にわかると思います. このRandom Responseで回答されたものを集計すると,個々の回答がどっちだったかの判別はつきませんが,回数の推定値が求められます. [tex:\sum{j} 1{\text {Support }\left(y^{j}\right)}(i)]をiと回答した人の人数とすると,以下の値が回数の不偏推定量になります.
証明は簡単にできますが,詳しいことは論文[3]を参照してください.
メカニズムの評価
ε-LDPを満たすメカニズムはいくつか考案されているので,どれが良いか評価をする必要があります. 実際の運用としては推定値が本当の値からあんまり離れていて欲しくありません. そこで,分散で評価をするということがよく行われています.
の大きさを各メカニズムごとに求めて,それを比べます.
これが小さいということは本当の値から外れた値が生成される確率が小さくなるため,実運用でもうまくいきそうということが分かります.
この分散をどうやって小さくするか,実際のデータでの誤差を小さくするというのがLDPの研究ではよく行われています.
まとめ
Differential Privacyについて,ちょっと冗長になってしまった気もしますが.なるべく詳しく説明してみました. ラプラスメカニズムは色々な手法で使われる基本的なものなので,わかっておくと良いと思います. また,それぞれのパラメータが何を意味しているのかなどもできるだけ説明したつもりなので,イメージもつきやすいかと思います.
最後少しだけLDPの説明をしましたが,LDPは実際にGoogleがブラウザでの情報を集めるのに使っているなど実応用とも関わりが強い分野です. 同様に複数のクエリに対するDPやストリーミングデータなどの実応用との関わりが深いDPについても説明したかったのですが, 少し長くなりすぎたので,次の記事で説明したいと思います. できれば毎週更新していきます.
参考文献
- 佐久間 淳,データ解析におけるプライバシー保護,講談社サイエンティフィク,2016.
- Cynthia Dwork. Differential privacy. Encyclopedia of Cryptography and Security, pp. 338-340, 2011.
- Tianhao Wang, Jeremiah Blocki, Ninghui Li, and Somesh Jha. Locally differentially private protocols for frequency estimation. In 26th USENIX Security Symposium, pp. 729-745, 2017
プライバシーの保護について
最近わけあって,プライバシー保護についての研究をしているので
自分のまとめ用兼文章を書く練習としてプライバシー保護について書いていこうと思います.
『データ解析におけるプライバシー保護』[1]を参考にしています.
言葉の定義
まず最初にプライバシーの話をしている最中によく出てくる用語を整理しておこうと思います.
個人情報
個人情報保護法では個人情報は以下のように定義される.
生存する個人に関する情報であって,当該情報に含まれる氏名,生年月日その他の記述などによって特定の個人を識別できるもの(他の情報と容易に照合することができ,それによって特定の個人を識別することができることとなるものを含む.),または個人識別符号が含まれるもの.
明確な範囲に関してはまだまだ議論されている最中であるが,氏名などを隠してあっても,突合することで個人を特定できそうな情報は全て個人情報となることに注意が必要である.
統計情報は,特定の個人との対応関係が排斥されている限りにおいては,個人情報ではなくなる.
暗号化だけではだめなことに注意する必要がある.
プライバシー
自己の情報をコントロールできる権利のこと.
自己の情報とは個人の私生活や秘密のことであり,これが他人から侵害されないことを保証するための権利.
間違えがちだが,プライバシーはあくまで権利のことで個人情報などのデータのことではない.
パーソナルデータ
[1]ではパーソナルデータは以下のように定義されている
従来の法律の枠組みにおいて個人情報に該当するかどうか明確になっていないが,プライバシー上の問題が存在するような種類の情報
問題になっているのはこのパーソナルデータをその事業者以外に提供する第三者提供である.個人情報の第三者提供は、原則として、本人の同意がない限りできないというルールになっているので,同意なしに提供してしまうとルール違反になる.
しかし,パーソナルデータは個人情報かどうかが曖昧であるので,同意なしに提供してしまい,後々ルール違反であることが発覚するということが多々ある.
その際,勘違いしているのが,データを匿名にしさえすれば提供して良いという考えである.匿名化をしても個人情報が復元可能な場合はそのデータも個人情報になるので,同意なしに提供してはいけない.
GDPR
一般データ保護規則というEU内での個人データやプライバシーの保護に関して様々なことを規定した規則のこと .
本人から個人情報の取扱いについての明確な同意を得ることや個人情報の取り扱いに関して透明性のある情報を提供することなどを要求している.
これに違反するとペナルティが課され,最近ではGoogleが62億円の制裁金を要求されるなどしている.
プライバシーはなぜ守られないといけないのか
個人情報は本人のものであるので,他人は勝手に個人情報を集めたり,使ったり,提供してはいけない.基本的人権の一つとして考えられているため,守られるべき当然の権利として考えられているが,詳しい話はちょっとわからない.
近年,技術の発展によりデータの利活用が進み,データ自体に価値があると考えられるようになった.その結果,データから知見を得るための分析が盛んに行われたり,そのためのデータの売買が行われたりと個人情報をどう扱い,守るかが問題になってきている.
実際プライバシーが侵害されたという事例がいくつかあるので紹介する.
プライバシー侵害の事例1
マサチューセッツ州のGroup Insurance Comission(GIC)は,135,000人の州職員とその家族について,医療保険に関連する情報を収集していた.
その情報には本人の氏名,性別,郵便番号,生年月日に加えて,医療機関の訪問日,診断結果などが含まれていた.
GICはそのデータから氏名を取り除いた上で,研究者に配布し,民間企業に販売していた.
一方,マサチューセッツ州ケンブリッジの選挙人名簿は民間人でも購入できた.選挙人名簿には選挙人の氏名,性別,郵便番号,生年月日に加えて,住所,登録日,支持政党などが含まれていた.
Seeneyはこの2つのデータに含まれる同一個人に関するデータを性別,生年月日,郵便番号を手掛かりに結びつけることができることを指摘した.[2]
医療保険のデータが個人を特定できる情報に復元されてしまった.すなわち,氏名などを削除した医療保険に関連する情報はまだ個人情報であり,これを配布したりしたことはルール違反だったのである.
プライバシー侵害の事例2
オンラインの動画ストリーミング会社Netflixは,推薦アルゴリズムのコンペティションを目的として,1999~2005年の間に約48万人の利用者が評価した映画のレイティング値約1億件を提供した.
提供データは,全データではなく一部がサンプリングされたデータで,利用者を直接的に特定する情報は提供データ中のレコードからは取り除かれていた.
Narayananらは,このような特定を防ぐ処理が施されたNetflixデータにおいて,攻撃者が犠牲者が犠牲者を一意に特定できる条件を統計的に導き,攻撃者が背景知識を持つならば,個人の特定が可能であると主張した.[3]
背景知識とは例えば,その個人が過去に与えた映画についてのレイティング値を知っており,そのレイティング値を与えた日付を詳しく知っていれば,個人のレコードを特定出来るなどである.
プライバシーを守る方法
このような攻撃者からどうやってプライバシーを守れば良いのだろうか.
特定の個人を識別することができないように個人情報を加工して、個人情報を復元することができないようにすれば良い.
このように加工した情報のことを「匿名加工情報」という.
上記の事例のように名前などの個人に関わる情報を削除しただけでは、攻撃を防げるとは限らない.
そこで,加工の度合いや攻撃のリスクを評価するk-匿名性とl-多様性の概念について説明し,
k-匿名性を実現する再符号化とマイクロアグリゲーションについて説明する.
k-匿名性
k-匿名性はどれだけ特定されるリスクがあるかを考慮するための指標で これを満たすようにデータを加工することでそのデータが持つリスクをコントロール出来る.
簡単にいうと,属性情報でデータを絞り込んでいっても最終的にはk人以下には絞れないということ.
住んでる場所,年齢,職業が一致するデータがどんな絞り込み方に対しても少なくともk個あるみたいな感じ.
l-多様性
k匿名性は個人の特定に関するリスクの評価であったが, l-多様性は属性推定のリスクを測るもの.
個人の特定は起きなくても、センシティブな属性が推定されるのはリスクであると考える.
例えば,ある特殊な病気にかかっているデータがあったとして,k-匿名性を保ったとしても
個人は特定されないが,特殊な病気にかかっていることは特定されてしまうかもしれない.
住んでる場所,年齢,職業が一致するデータでかかっている病気という欄の値のバリエーションがどんな絞り込み方に対しても少なくともl個あるみたいな感じ.
これはセンシティブな属性でだけ満たされていれば良い.
再符号化
カテゴリーや順序属性のための加工法で,複数のカテゴリ値を一つのより抽象度の高いカテゴリに統合する.
年齢を1刻みから10刻みに変更したり,住所を都道府県にまとめたりする.
単に上位のカテゴリに統合するだけでなく,トップコーディングとボトムコーディングという手法もある.
トップコーディングは80歳以上を一つにするなど,ある閾値以上を一つにまとめる手法.
ボトムコーディングはある閾値以下をまとめる手法であり,裾に当たるような頻度の低い属性を1つにまとめることが出来るので,k-匿名性を維持するのに役立つ,
どんなレコード集合に対しても,厳密にk-匿名性を維持する手法は,かなりの組み合わせを考えないといけないので難しい.
マイクロアグリゲーション
数値属性を対象にした加工法.
k-meansなどのクラスタリングによって、複数の値をまとめる手法.
各クラスターにおけるレコードがk個以上になるようなクラスターを作り,そのグループの数値属性を代表値で置き換える.
年収などでクラスタリングして,300~315万が一つのグループになったとしたら310万などを代表値として,置き換えることでk-匿名性を維持する.
まとめ
プライバシーについての用語の整理と匿名加工などの一般的な手法について説明しました. 最初の用語の確認のところの個人情報は勘違いが多いところらしいので,きちんと読んでくれると嬉しいです. まだ勉強を始めたばかりなので,間違い等あれば指摘して頂けるとありがたいです.
図とかを使って説明したかったけど,その気力がなくて諦めてしまったので,余力があれば今度追加するかもしれないです.
最近プライバシー保護で注目されているDifferential Privacyについては次の記事で紹介します.
文章の構成とか書いている内容とか変な感じがするけど 投稿を続けるうちに良くなっていくと信じて頑張っていこうと思います.
参考文献
- 佐久間 淳,データ解析におけるプライバシー保護,講談社サイエンティフィク,2016.
- Sweeney, Latanya. "k-anonymity: A model for protecting privacy." International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems 10.05 (2002): 557-570.
- Narayanan, Arvind, and Vitaly Shmatikov. "Robust de-anonymization of large datasets (how to break anonymity of the Netflix prize dataset)." University of Texas at Austin (2008).