データ品質の現在地を測る
この記事は、クリスマスに向けデータに関する想いや技術をぶっちゃける Advent Calendar 2022 22日目の記事です。
はじめに
朝出勤すると、昨日のデータが連携されていなかったり、ダッシュボードの形が極端に変わっていたりとデータ基盤の障害に悩まされたことはありませんか?
多くの人が頷いてくれるのではないでしょうか。
ただ、データの品質を高めたいと思っても、DMBOKなどに書かれているデータ品質の内容は、大事な事柄がリストアップしてあるだけで、具体的にどうしたら良いかのイメージが湧きにくいです。
そんな中、Monte Carlo社が書いた Data Quality Fundamentals (この記事で書籍といった場合はこの本を指します)という本がとても実践的で面白かったので、その内容を紹介したいと思います。
この記事がデータ品質について考えるきっかけになり、データ基盤の障害に悩まされる人を少しでも減らせれば幸いです。
データ品質の重要性
そもそもデータ品質とは何でしょうか。
DMBOKには「データ品質の度合いはデータ利用者の期待と要求を満たす度合である」とあり、絶対的な基準のようなものはなく、目的に合っているかどうかが重要になります。 すなわち、月次で経営に報告する指標であれば、リアルタイムでデータが必要なわけではないが、数値に少しでもズレがあれば低品質なデータになります。
では、なぜデータ品質は重要なのでしょうか。
これはWebサービスの発展を考えるとわかりやすいです。 1990年代には、Webサービスはあったらいいな程度の存在で、一時的にダウンしても大した問題ではありませんでした。現在、Webサービスはほとんどの企業にとってミッションクリティカルなものとなっています。その結果、企業はダウンタイムを綿密に測定し、サービスの中断を回避するために多くのリソースを投入しています。
同様に、企業は日々業務を遂行し、ミッションクリティカルな意思決定を行うために、ますますデータへの依存を高めているため、データ品質が重要になってきているのです。
実際、Monte Carlo社が、Wakefield Research社と提携し、300人以上のデータプロフェッショナルを対象にした調査によると 、データ担当者がデータ品質の評価やチェックに費やす時間は実に40%にのぼり、データ品質の低下は企業の収益の26%に影響するというデータ品質の重要性を示す調査結果が得られています。
データ品質を計測する指標
「測定できないものは管理できない」「推測するな、計測しろ」と言われるように、データ品質に関する指標なしに、データ品質を管理することはできません。 では、どのような指標を使えば良いのでしょうか。
書籍では、以下の「データダウンタイムコスト(Cost of data downtime)」という指標が提案されています。 (この辺は変に日本語訳しない方が良いかもですが、日本語でいきます)
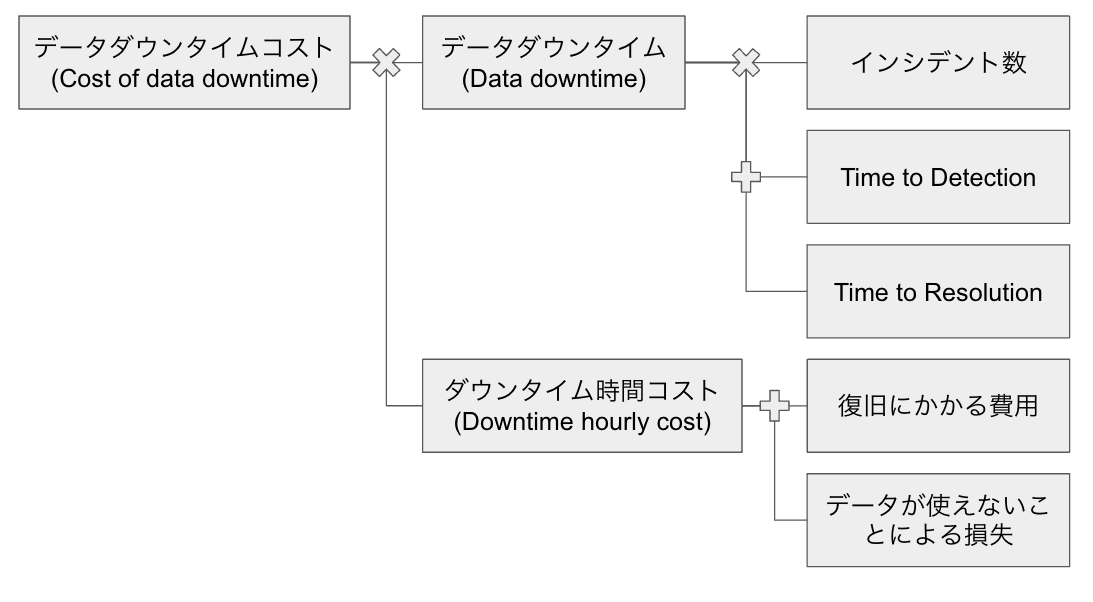
データダウンタイムコスト = データダウンタイム×ダウンタイム時間コスト
データダウンタイム: データが正常でない時間
ダウンタイム時間コスト: データの復旧に費やした労働のコスト+ユーザーがデータを使えないことによる単位時間あたりの損失
自分はこの指標を最初見たとき、衝撃を受けました。データ品質は利用者によって決まるということと、ビジネスへの影響を上手く表現している指標だったからです。 以下でもう少し詳細に説明していこうと思います。
データダウンタイム
データダウンタイムはより詳細には下記で表されます。
データダウンタイム=N×(TTD+TTR)
N: データインシデント数
TTD(Time to Detection): データ品質の問題の発生からデータチームが発見するまでにかかる時間
TTR(Time to Resolution): 問題の発見後、データチームが解決するまでにかかる時間
インシデントの定義は、およそ2通りの方法があり、それらの合計をインシデント数とすることができます。
1つ目の定義は事前に定義したテストに失敗した場合です。これはPKやNullなどをテーブルに対してチェックするクエリを投げてその結果を見ることで検知することができます。
2つ目の定義は、利用者が異変に気づいてデータチームにアラートをあげた場合です。テスト項目を事前に網羅的に定義することは基本的に不可能です。異変を感じたらすぐにアラートを上げてもらうようにしましょう。
TTDやTTRは、アラートが上がった時間や修正後にデータが連携された時間などをシステムから取得して算出できるかと思います。 データダウンタイムとしてはTTDやTTRは平均値がわかれば良いのですが、最小値や最大値なども重要なデータになります。
ダウンタイム時間コスト
ダウンタイム時間コストは以下で表されます。
ダウンタイム時間コスト = 復旧にかかる費用 + データが使えないことによる損失
データダウンタイムとは違って、システムから取得することは難しいですが、ある程度仮定をおくことで計算できます。
復旧にかかる費用は、エンジニアの労働時間で計算します。
例えば、1人のデータエンジニアがダウンタイム時間の1/4を監視や調査に費やしており、給与が時給4000円とすると、ダウンタイム時間あたり1000円のコストがかかっていると推定できます。
データが使えないことによる損失は、業務によって大きく異なります。
例えば、投資会社に報告するためにデータを利用している場合、データのダウンタイムは致命的で、10万円/時間が損失として加算されます。
また、分析チームのコストを追加することもできます。例えば、アナリストが10人いて、ダウンタイムが発生したときに彼らが休んでいるとすると、かなりの損失になります(平均時給5000円×10=5万円/時間)。
この辺りは勝手に決めてもあまり意味がないので、上層部や周辺の組織と相談しながら詳細を詰めていきましょう。
ちょっとした計算
データダウンタイムコストの計算を仮の数値で、実際にしてみようかと思います。
モンテカルロ社の調査の結果、年間15テーブルに1テーブルがデータインシデントの影響を受けていること、インシデントの発生から発見までに4時間以上、発見後の解決までに平均9時間かかっていることが判明しました。
例えば、1000テーブルあるとすると
データダウンタイム = 1000×1/15 × (4+9) ≒ 867 時間/年
になります。
時給4000円のエンジニアが2人、ダウンタイムの1/4を監視や調査に費やしており、時給5000円のデータアナリストが10人、ダウンタイムの1/5の時間稼働できていないとすると
ダウンタイム時間コスト = 4000×2×1/4 + 5000×10×1/5 = 12000 円/時間
ダウンタイムコストは少なく見積もっても約1040万円/年になります。
データダウンタイムを20%改善できたとすると、少なくとも年間208万円のコスト削減になるだけでなく、今後扱うデータが増えることによるダウンタイムの増加を軽減することができます。
そして、これらの指標は、改善ポイントの見極めに使うこともできます。
TTDが大きければ、アラートの仕組みなど異常を検知できる仕組みが不十分な可能性があり、TTRが大きければ、データパイプラインが複雑化しており、技術的負債が溜まっている可能性があります。
また、データが使えないことによる損失が大きいテーブルは重要なテーブルで、そこに紐づくパイプラインは厳重にするなどの対策が可能です。
まとめ
本記事では、データの不備が与える金銭的影響を測定する指標の計算方法を紹介しました。ぜひ皆さんも自分たちのデータ基盤の品質を測定してみてください。 ただ、指標を定義するだけはもちろんダメで、それを改善するために効果的なプラットフォームの構築や文化・組織づくりといった取り組みが必要です。(こちらの記事もまた書くかもしれません)
本記事では紹介しきれませんでしたが、インシデント管理のベストプラクティスやデータ品質を大規模に普及させる際の文化・組織の障壁、Toast社のデータ基盤の変遷に関するケーススタディなど、書籍には興味深いトピックスが盛りだくさんなので、データ品質に興味を持たれた方はぜひ書籍の方も読んでみてください。
今後、データ品質は必ず重要になると思っているので、自分でも実践していければと思います。 最後まで読んでくださり、ありがとうございました。